
Generative AI: commodity or core business?
04 March 2024
The choice between buying or developing generative AI in-house depends on the use, the data and the competitive advantage sought. Eleven proposes a methodology for…
Data science
Generative AI
Innovation
After “NFT” in 2020/21, “metaverse” in 2021/22, “ChatGPT” could undoubtedly be considered the “buzzword of the year 2022/23”. Acclaimed or unsung, it is hotly debated on TV shows, social networks and within companies. Is it the emergence of a revolutionary technology, in the same way as the advent of micro-processors, as Bill Gates points out, or simply “the popularization of an already existing technology”, as Yann LeCun, AI Scientific Director at Facebook, puts it?
The answer probably lies somewhere in between. Yes, ChatGPT brings many advances in terms of human language processing. Used skilfully, it can significantly improve the performance of certain AI models, previously at the cutting edge of technology. But behind ChatGPT lie language models that have been known for several years, already widely used and exploited by AI experts, notably at eleven, where they have been used for more than a dozen projects for industrial players and start-ups.
ChatGPT, the chatbot developed by OpenAI, is one application of a technology that has been booming since 2018: LLMs, or Language Learning Models. Sometimes also referred to as “foundation models”, they are the core of machine understanding of human language. To do this, they rely on a complex architecture of neural networks, and hundreds of billions of parameters to be adjusted iteratively. The principle is simple: for a given sample sentence, predict the next word.
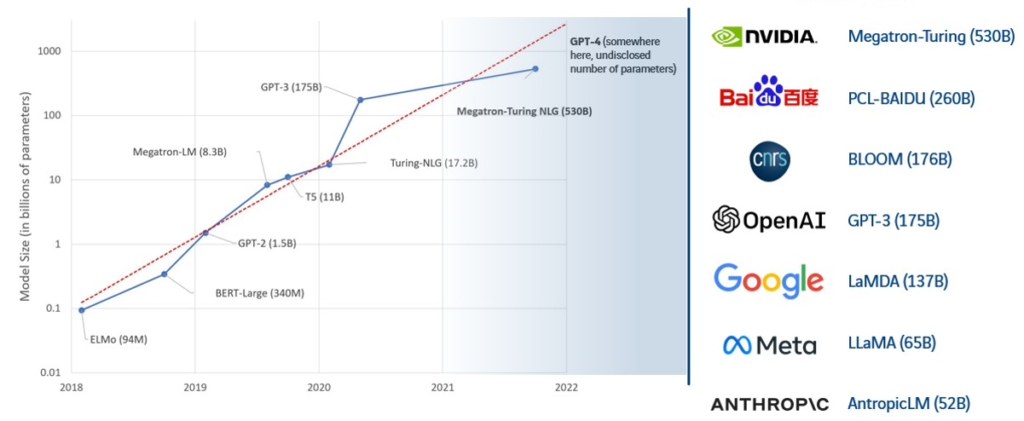
The AI thus determines the meaning of a word by taking into account the contexts in which it has encountered it. Training a model with so many parameters requires a large amount of data, generally taken from publicly accessible data such as Wikipedia (3% of the training corpus), press articles, open-access books, and so on. As an example, GPT-3 (Generative Pre-trained Transformers-3), composed of 175 billion parameters, required the ingestion of almost 570 GB of data, or around 300 billion words. These pharaonic figures are synonymous with considerable financial costs: we’re talking about 4.6 million dollars spent on training GPT-3, not to mention the resulting ecological impact.
Figure 1: Trend in the number of parameters used by LLMs models since 2018 (4).

The result is very powerful AI models, capable of understanding all the semantics of each language on which they have been trained, enabling them to carry out numerous use cases: text translation, essay writing, etc… More broadly, they can be specialized, i.e. adapted to a use case, giving them a wide range of possible tasks, like ChatGPT.
ChatGPT is a chatbot based on GPT-3 capable of emulating the human experience of a real conversation. Thirteen thousand question/answer pairs were used to transform a “next word prediction” model into one capable of answering questions. In parallel, a reward model – reinforcement learning – helps ChatGPT to orient itself towards producing answers expected by a human. This final stage, during which humans rank different possible answers to the same question, enables the moderation of certain content considered illegal or dangerous.
Despite its remarkable performance, ChatGPT suffers to date from severe ethical and technical limitations.
From an ethical point of view, the technology faces a number of significant issues, linked to its operation and training process.
LLMs based on open data and available as open source such as Alpaca, developed by Stanford, meet the limits of confidentiality and intellectual property, but perform less well and remain susceptible to bias and harmful content.
ChatGPT provides a plausible response, which denotes the least, given all the contexts it has encountered during its training. It is therefore unfamiliar with the concept of truth. From this key point arise several technical limitations:
Several options exist to get around these technical limitations: using frameworks to source information and search external sources (such as LangChain), using GPT-4 (the latest and more powerful paid version of OpenAI), or specializing ChatGPT to specific use cases.
Fortunately, it’s not primarily a question of training a language model from scratch, but of taking advantage of its language learning to get it to perform specific tasks. This is known as “Transfer Learning”, when a pre-trained model is adjusted to a specific use case, a step which is significantly less energy-intensive.
ChatGPT is a useful and promising technology, which could be used in many fields in the future. At eleven, we’re seeing the kind of interest from different professions that matches the media coverage of the subject, and we’re talking to them about numerous applications :
More generally, language models can be put to use for many tasks, from process automation, to complex human tasks, such as data analysis and document processing.
The projects eleven has supported have, however, highlighted certain prerequisites for effective use of the technology:
Following these guidelines, we improved the local development plan with key information extraction performance from 13% with a Plug & Play method, to 55% with good corpus pre-selection and prompt engineering. Note that the best performance achieved without language models is 26% for such a subject, twice as good as GPT without adjustments, and half as good as GPT with support.
Eleven supports companies in the experimentation, development and integration of these tools for concrete use cases. With a strategic approach, realistic expectations, and above all a clear understanding of how it works and its limitations, companies can truly benefit from the technology behind ChatGPT.
(1) https://www.independent.co.uk/tech/harvard-chatbot-teacher-computer-science-b2363114.html
(2) https://fr.wikipedia.org/wiki/GPT-3
(3) https://arxiv.org/pdf/2302.04023.pdf
(4) https://huggingface.co/blog/large-language-models
Share
Sur le même sujet
04 March 2024
The choice between buying or developing generative AI in-house depends on the use, the data and the competitive advantage sought. Eleven proposes a methodology for…

29 November 2023
Unlock business transformation with large language models (LLMs). Explore real-world impacts, challenges and use cases. Improve your strategy with Eleven's expertise in AI and innovation.